I am a third-year undergraduate at Yuanpei College, Peking University, majoring in Intelligence Science and Technology, and I expect to graduate in 2027. I am currently a summer research intern at Carnegie Mellon University, working with Prof. Guanya Shi.
My research, advised by Prof. Yue Wang and Prof. Hao Dong, focuses on Embodied AI, Dexterous Manipulation, and Humanoid Robots. Broadly, I am interested in building general-purpose robots that perceive, learn, and act robustly in the unstructured physical world. I have also collaborated with Prof. Pieter Abbeel and Prof. Jitendra Malik at Sharpa.
I am applying for PhD programs in the 2026–2027 cycle (Fall 2027 admission).
🔥 News
- 2026.04: 🎉🎉 ViTacFormer is accepted by RSS 2026.
- 2026.01: 🎉🎉 Imagine2Act is accepted by ICRA 2026.
- 2025.08: 🎉🎉 3DS-VLA is accepted by CoRL 2025.
- 2025.06: 🎉🎉 RwoR is accepted by IROS 2025 (Oral).
📝 Publications

HumDex: Humanoid Dexterous Manipulation Made Easy
Liang Heng, Yihe Tang, Jiajun Xu, Henghui Bao, Di Huang, Yue Wang
Cite (BibTeX)
@article{heng2026humdex,
title={Humdex: Humanoid dexterous manipulation made easy},
author={Heng, Liang and Tang, Yihe and Xu, Jiajun and Bao, Henghui and Huang, Di and Wang, Yue},
journal={arXiv preprint arXiv:2603.12260},
year={2026}
}
ViTacFormer: Learning Cross-Modal Representation for Visuo-Tactile Dexterous Manipulation
Liang Heng, Haoran Geng, Kaifeng Zhang, Pieter Abbeel, Jitendra Malik
Cite (BibTeX)
@article{heng2025vitacformer,
title={ViTacFormer: Learning cross-modal representation for visuo-tactile dexterous manipulation},
author={Heng, Liang and Geng, Haoran and Zhang, Kaifeng and Abbeel, Pieter and Malik, Jitendra},
journal={arXiv preprint arXiv:2506.15953},
year={2025}
}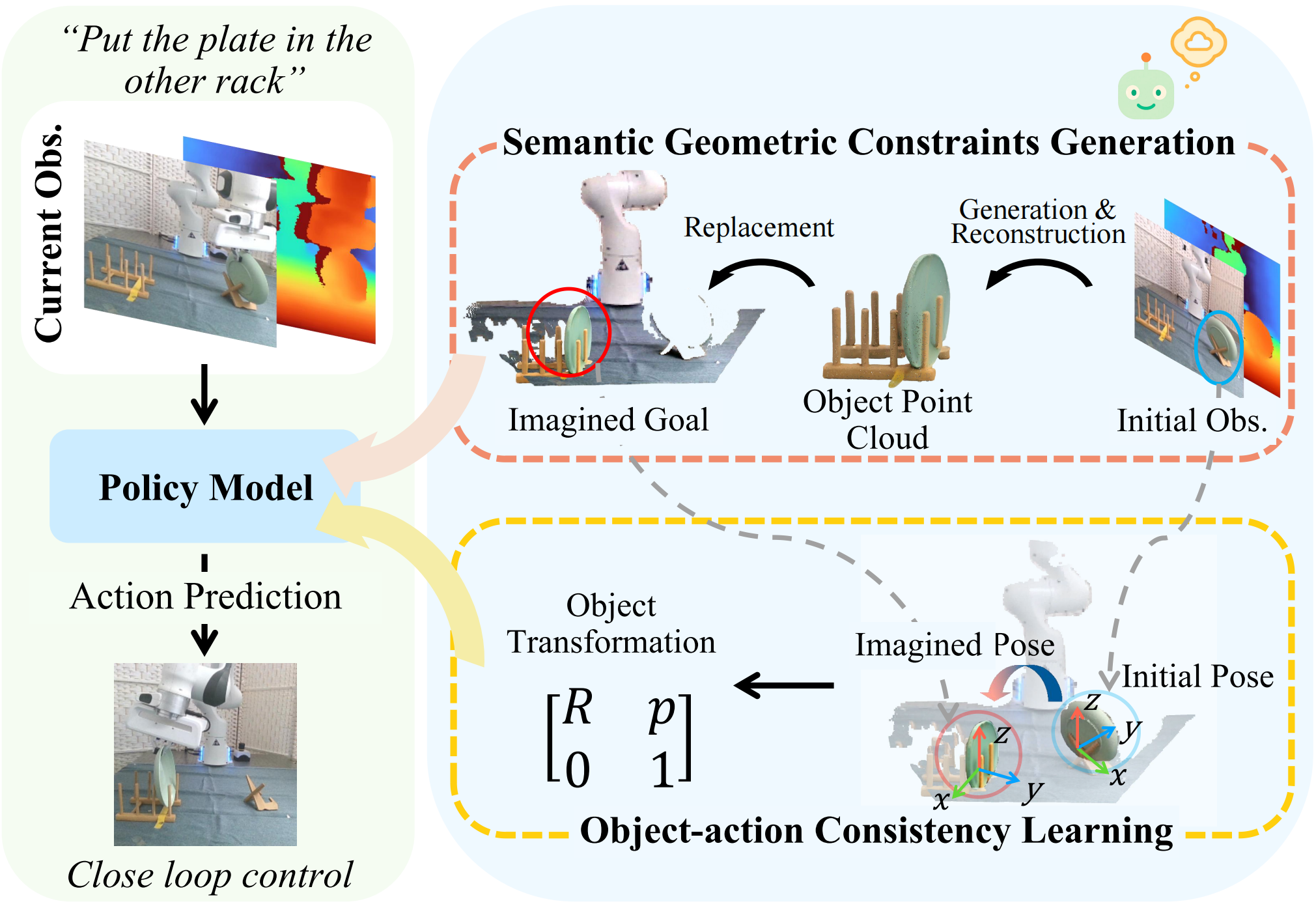
Liang Heng, Jiadong Xu, Yiwen Wang, Xiaoqi Li, Muhe Cai, Yan Shen, Juan Zhu, Guanghui Ren, Hao Dong
Cite (BibTeX)
@article{heng2025imagine2act,
title={Imagine2Act: Leveraging Object-Action Motion Consistency from Imagined Goals for Robotic Manipulation},
author={Heng, Liang and Xu, Jiadong and Wang, Yiwen and Li, Xiaoqi and Cai, Muhe and Shen, Yan and Zhu, Juan and Ren, Guanghui and Dong, Hao},
journal={arXiv preprint arXiv:2509.17125},
year={2025}
}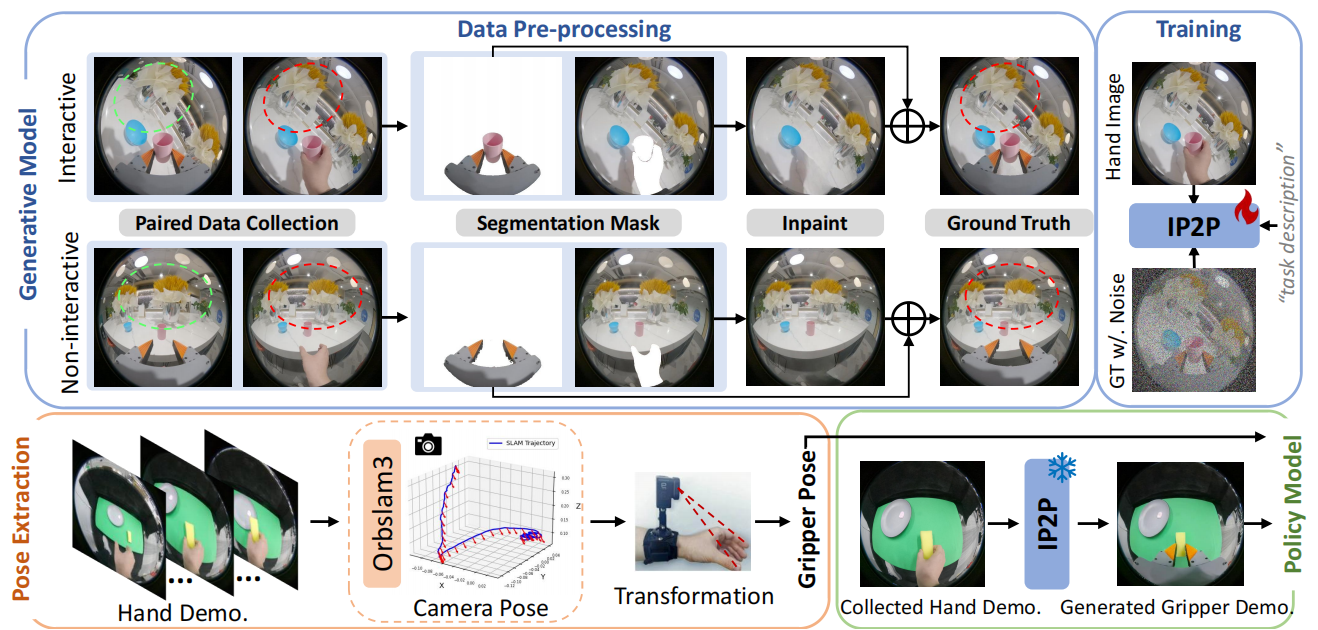
RwoR: Generating Robot Demonstrations from Human Hand Collection for Policy Learning without Robot
Liang Heng, Xiaoqi Li, Shangqing Mao, Jiaming Liu, Ruolin Liu, Jingli Wei, Yu-Kai Wang, Yueru Jia, Chenyang Gu, Rui Zhao, Shanghang Zhang, Hao Dong
Cite (BibTeX)
@inproceedings{heng2025rwor,
title={Rwor: Generating robot demonstrations from human hand collection for policy learning without robot},
author={Heng, Liang and Li, Xiaoqi and Mao, Shangqing and Liu, Jiaming and Liu, Ruolin and Wei, Jingli and Wang, Yu-Kai and Jia, Yueru and Gu, Chenyang and Zhao, Rui and others},
booktitle={2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
pages={13544--13551},
year={2025},
organization={IEEE}
}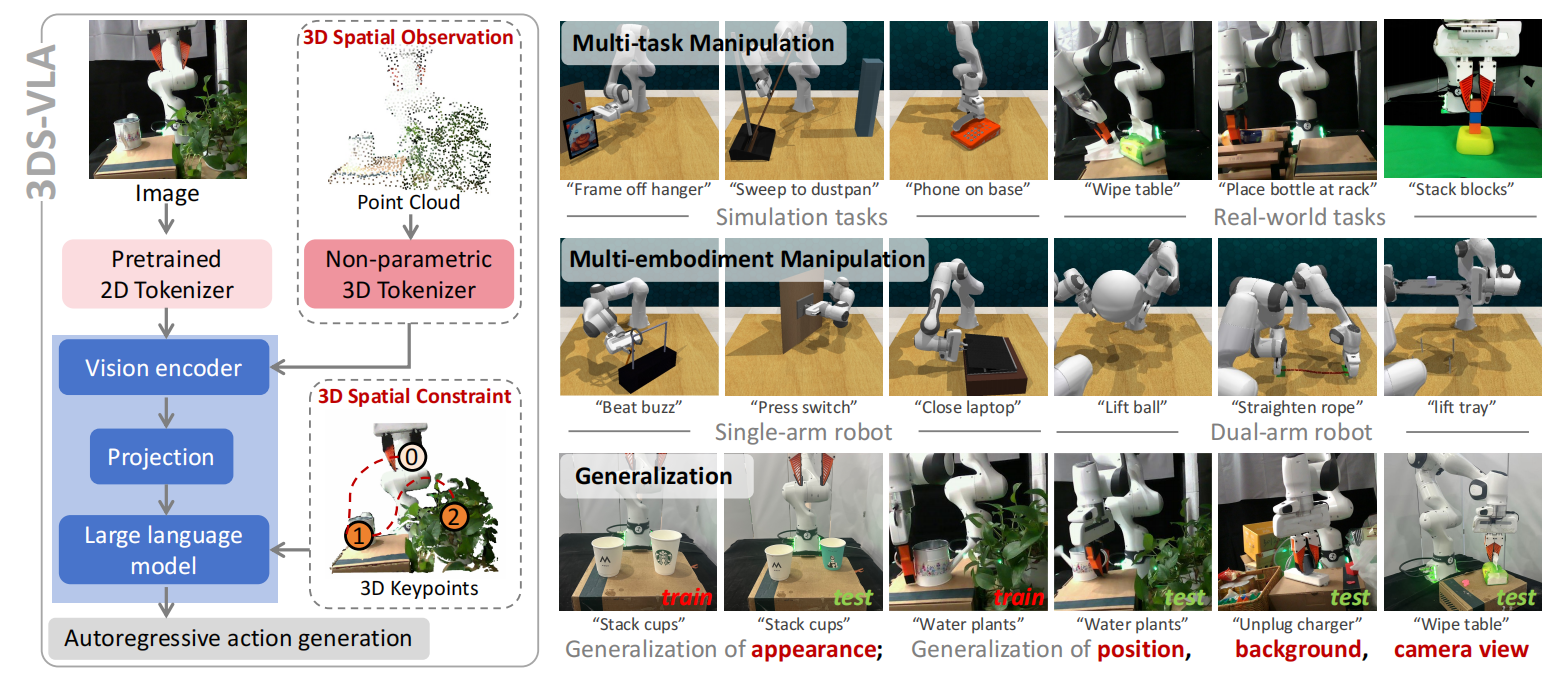
3DS-VLA: A 3D Spatial-Aware Vision Language Action Model for Robust Multi-Task Manipulation
Xiaoqi Li, Liang Heng, Jiaming Liu, Yan Shen, Chenyang Gu, Zhuoyang Liu, Hao Chen, Nuowei Han, Renrui Zhang, Hao Tang, Shanghang Zhang, Hao Dong
Cite (BibTeX)
@inproceedings{li20253ds,
title={3ds-vla: A 3d spatial-aware vision language action model for robust multi-task manipulation},
author={Li, Xiaoqi and Heng, Liang and Liu, Jiaming and Shen, Yan and Gu, Chenyang and Liu, Zhuoyang and Chen, Hao and Han, Nuowei and Zhang, Renrui and Tang, Hao and others},
booktitle={9th Annual Conference on Robot Learning}
}
SIMPLE: Simulation-Based Policy Learning and Evaluation for Humanoid Loco-manipulation
Songlin Wei, Zhenhao Ni, Jie Liu, Zhenyu Zhao, Junjie Ye, Hongyi Jing, Junkai Xia, Xiawei Liu, Michael Leong, Liang Heng, Di Huang, Yue Wang
Cite (BibTeX)
@article{wei2026simple,
title={SIMPLE: Simulation-Based Policy Learning and Evaluation for Humanoid Loco-manipulation},
author={Wei, Songlin and Ni, Zhenhao and Liu, Jie and Zhao, Zhenyu and Ye, Junjie and Jing, Hongyi and Xia, Junkai and Liu, Xiawei and Leong, Michael and Heng, Liang and Huang, Di and Wang, Yue},
journal={arXiv preprint arXiv:2606.08278},
year={2026}
}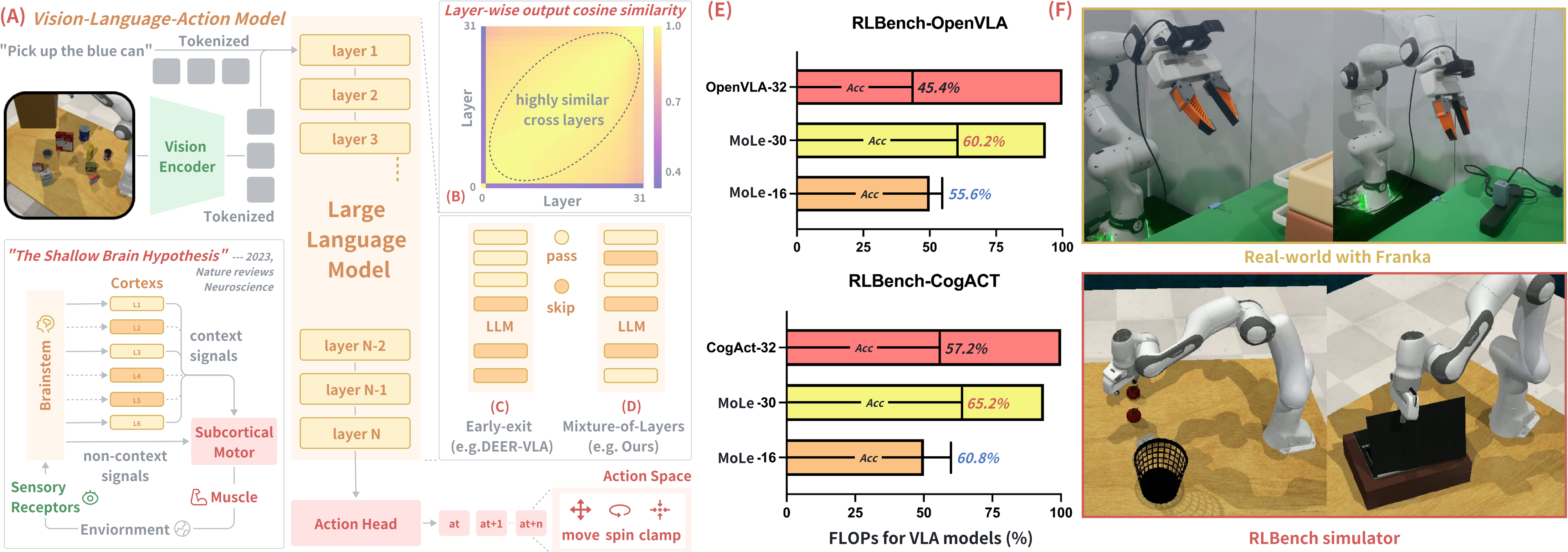
Rongyu Zhang, Menghang Dong, Yuan Zhang, Liang Heng, Xiaowei Chi, Gaole Dai, Li Du, Yuan Du, Shanghang Zhang
Cite (BibTeX)
@inproceedings{zhang2026mole,
title={Mole-vla: Dynamic layer-skipping vision language action model via mixture-of-layers for efficient robot manipulation},
author={Zhang, Rongyu and Dong, Menghang and Zhang, Yuan and Heng, Liang and Chi, Xiaowei and Dai, Gaole and Du, Li and Wang, Dan and Du, Yuan and Zhang, Shanghang},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={40},
number={22},
pages={18764--18772},
year={2026}
}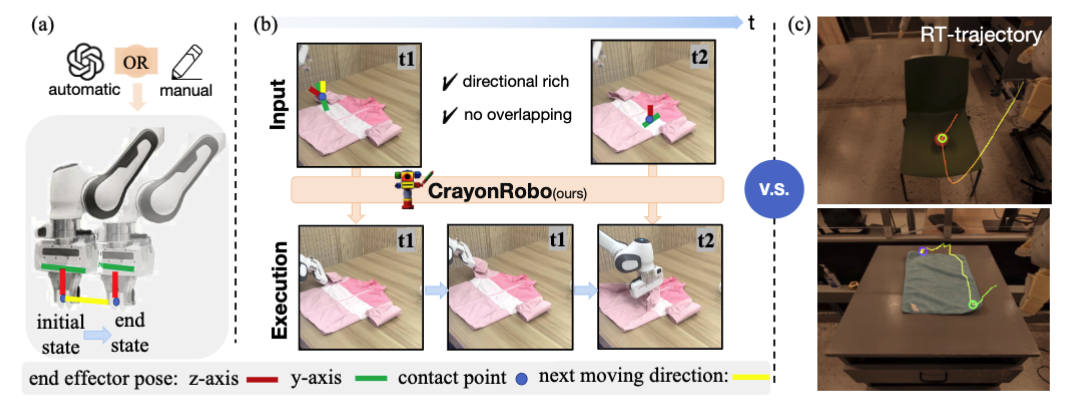
CrayonRobo: Object-Centric Prompt-Driven Vision-Language-Action Model for Robotic Manipulation
Xiaoqi Li, Lingyun Xu, Mingxu Zhang, Jiaming Liu, Yan Shen, Iaroslav Ponomarenko, Jiahui Xu, Liang Heng, Siyuan Huang, Shanghang Zhang, Hao Dong
Cite (BibTeX)
@article{li2025crayonrobo,
title={Crayonrobo: Object-centric prompt-driven vision-language-action model for robotic manipulation},
author={Li, Xiaoqi and Xu, Lingyun and Zhang, Mingxu and Liu, Jiaming and Shen, Yan and Ponomarenko, Iaroslav and Xu, Jiahui and Heng, Liang and Huang, Siyuan and Zhang, Shanghang and others},
journal={arXiv preprint arXiv:2505.02166},
year={2025}
}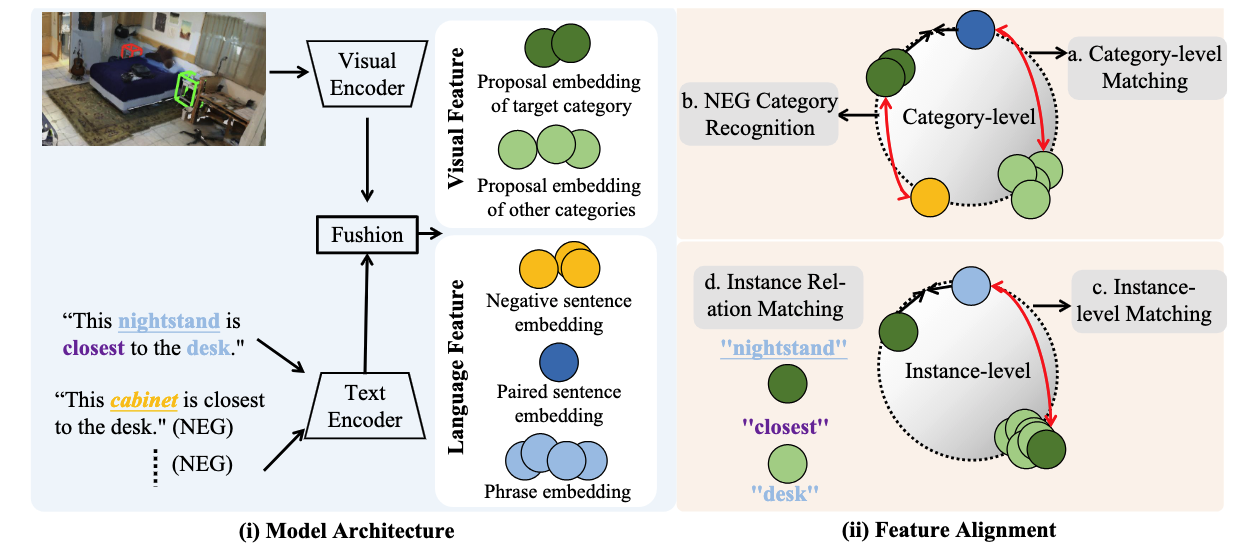
3D Weakly Supervised Visual Grounding at Category and Instance Levels
Xiaoqi Li, Jiaming Liu, Nuowei Han, Liang Heng, Yandong Guo, Hao Dong, Yang Liu
Cite (BibTeX)
@inproceedings{li20253dwg,
title={3dwg: 3d weakly supervised visual grounding via category and instance-level alignment},
author={Li, Xiaoqi and Liu, Jiaming and Han, Nuowei and Heng, Liang and Guo, Yandong and Dong, Hao and Liu, Yang},
booktitle={2025 IEEE International Conference on Robotics and Automation (ICRA)},
pages={12766--12773},
year={2025},
organization={IEEE}
}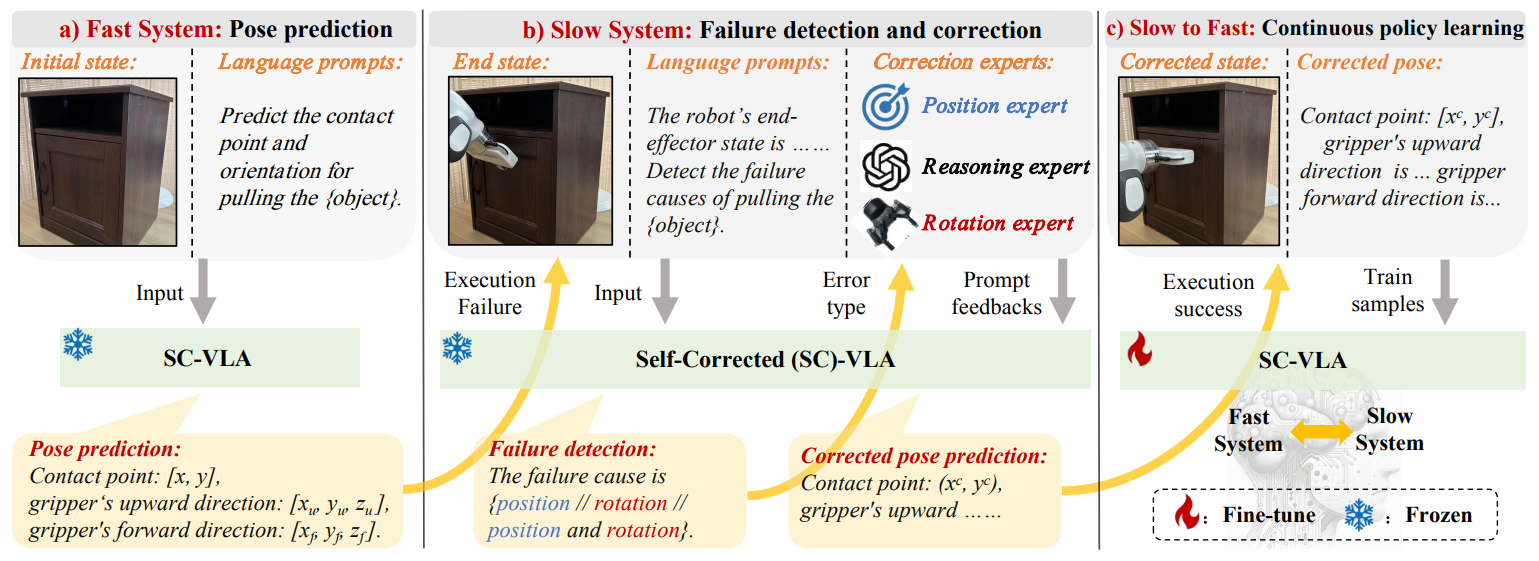
A Self-Correcting Vision-Language-Action Model for Fast and Slow System Manipulation
Chenxuan Li, Jiaming Liu, Guanqun Wang, Xiaoqi Li, Sixiang Chen, Liang Heng, Chuyan Xiong, Jiaxin Ge, Renrui Zhang, Kaichen Zhou, Shanghang Zhang
Cite (BibTeX)
@article{li2024self,
title={A Self-Correcting Vision-Language-Action Model for Fast and Slow System Manipulation},
author={Li, Chenxuan and Liu, Jiaming and Wang, Guanqun and Li, Xiaoqi and Chen, Sixiang and Heng, Liang and Xiong, Chuyan and Ge, Jiaxin and Zhang, Renrui and Zhou, Kaichen and others},
journal={arXiv preprint arXiv:2405.17418},
year={2024}
}🎖 Honors and Awards
- 2026 SenseTime Scholarship.
- 2026 Academic Star of Hope, Yuanpei College, Peking University.
- 2025 Yuanpei Young Scholar, Peking University.
- 2023 Freshman Scholarship, Peking University.
📖 Educations
- 2023.09 - 2027.06 (expected), B.S. in Intelligence Science and Technology, Yuanpei College, Peking University, China.
💻 Internships
- 2025.11 - 2026.07, Research Intern, WorldEngine AI, Los Angeles, USA.
- 2025.03 - 2025.08, Research Intern, Sharpa, Shanghai, China.
- 2024.07 - 2025.03, Research Intern, PKU-Agibot Joint Lab, Beijing, China.
📄 Research Experiences
- 2026.07 - Present, working as a summer research intern at the LeCAR Lab, Carnegie Mellon University, advised by Prof. Guanya Shi.
- 2025.11 - 2026.07, working as a research intern at the Physical Superintelligence (PSI) Lab, USC, advised by Prof. Yue Wang.
- 2025.03 - 2025.08, working as a research intern at Sharpa, collaborating with Prof. Pieter Abbeel and Prof. Jitendra Malik.
- 2024.07 - 2025.03, working as a research intern at the PKU-Agibot Joint Lab, advised by Prof. Hao Dong.
👁️ Total visits: ··· | Visitors: ···